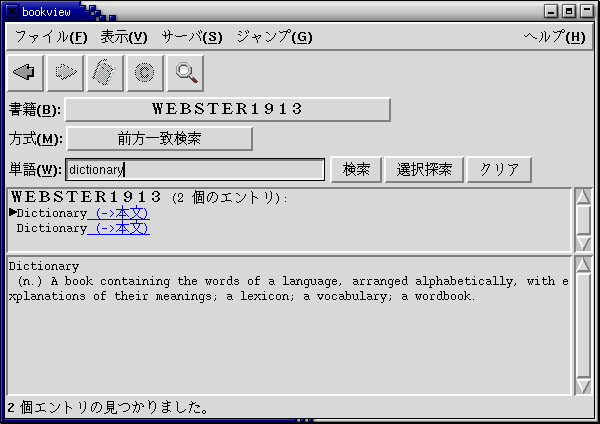
 EBStuidio
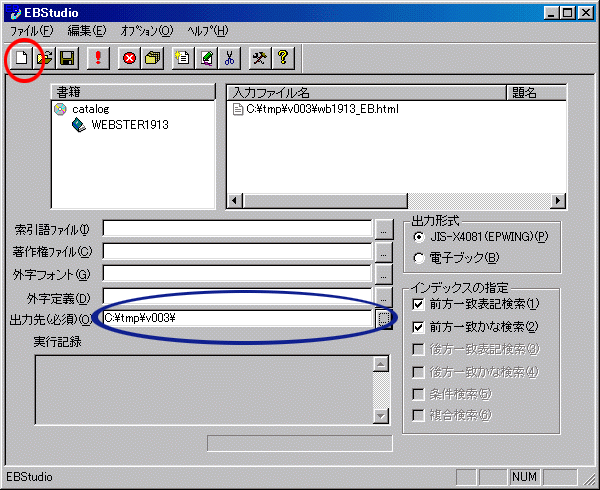
を起動して,html形式のデータをEPWING形式に変換します。まず、「ファイル」-「新規作成」または、メニューバーの左端(下図の赤丸)をクリックします。
EBStuidio
を起動して,html形式のデータをEPWING形式に変換します。まず、「ファイル」-「新規作成」または、メニューバーの左端(下図の赤丸)をクリックします。 「書籍情報の登録」のWindowが開きますので、ここで書籍名と辞書を格納するディレクトリを指定します。書籍名はなんでもよいのですが、WEBSTER1913
としました。
「書籍情報の登録」のWindowが開きますので、ここで書籍名と辞書を格納するディレクトリを指定します。書籍名はなんでもよいのですが、WEBSTER1913
としました。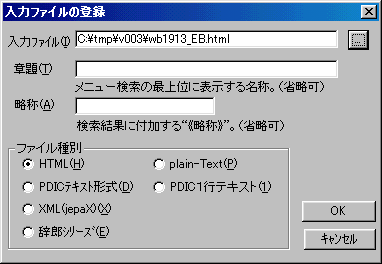 「OK」とすると次に「入力ファイルの登録」Windowが開くので、先程作成したhtmlファイルを指定します。ファイル種別で「HTML」にチェックが入っていることを確認した後、
「OK」とすると次に「入力ファイルの登録」Windowが開くので、先程作成したhtmlファイルを指定します。ファイル種別で「HTML」にチェックが入っていることを確認した後、
「OK」を入力して、元のWindowにもどって、EPWING形式のデータを格納する出力先を指定します。指定した出力先の下に、catlogsと書籍情報で登録した書籍ディレクトリが作成されます。
以上の準備がおわったら、!をクリックすると変換が始まります。
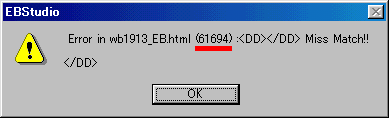 Websterの原データは色々誤りは修正されてきているようですが、ところどころに誤りがあって、変換途中で右図のようなエラーメッセージがでることがあります。赤線を引いたところに表示されているのがエラーの有る行数ですから、エディタ等で元の
htmlデータの指定行を開いて確認の上、修正をします。例えばこの場合は、sedで指定行の前後を確認すると
Websterの原データは色々誤りは修正されてきているようですが、ところどころに誤りがあって、変換途中で右図のようなエラーメッセージがでることがあります。赤線を引いたところに表示されているのがエラーの有る行数ですから、エディタ等で元の
htmlデータの指定行を開いて確認の上、修正をします。例えばこの場合は、sedで指定行の前後を確認すると
| $ sed -n '61693,61695p' wb1913_EB.html
<DT>Foretoken</DT><DD> (<I>v. t.</I>) To foreshow; to presignify; to prognosticate.</DD></BR> </DD></BR> <DT>Fore teeth</DT><DD> (<I>pl. </I>) of Fore tooth</DD></BR> |
なお、最終的に変換時間は数分でした。