We were recently asked by a client if the SoapBox Server 2007 could handle 1 million simultaneous users on a single machine. The SoapBox Server 2007 is a .NET 2.0 beast that runs on x86, x64 and Itanium platforms and has been tested without issue up to 100,000 simultaneous users.
The problem with answering the question, “Can you hit a MegaUser?” is that we don’t know the answer. Like most small companies (and even a few small countries), hardware of the scale required is out of our budget range. Dual Core laptops and desktops? No problem. Eight and 16 way machines with 48GB+ of memory? No thank you, not today. That BMW M6 sure looks nice though, and it’s much cheaper. Can I have one of those instead?
Through our partnership with HP (thank you Donna!) we got access to some of the very cool Itanium hardware. Specifically they gave us exclusive access for a week to a pair of 16 processor Itanium2 machines each with 64GB of memory. They even threw a few tadpoles in with the sharks - a quad proc for the database, and a dual proc for whatever else we needed.
I’m going to assume that those of you reading this are familiar with threads and the various techniques for dealing with them. If not, there is a lot of material on the Internet covering basic threading under Windows and C# - just look for stuff written by Richter and begin reading.
Now, some quick background on our server:
The SoapBox Server is a heavily multithreaded server designed around Asynchronous Sockets. When running on Windows 2000, XP, 2003, Vista, and Longhorn this means that we get to use the entire IO Completion Port (IOCP) infrastructure for all of our socket operations. From a practical perspective this means that we call “BeginRead()” on all of our sockets, and whenever data arrives on a socket we magically get a callback from Windows with the right data. No use of the dreaded “1 Thread Per Socket” pattern and no use of the BSD style select pattern the Unix folk tend to use.
SoapBox Server, Stage 1
Our first architecture, years ago, had data coming in from the sockets, processed into valid xml stanzas, appended to a queue, and then the socket put back into BeginRead Mode.

As an architectural pattern, this is a fairly common way to go:
1. Pull data from socket
2. Queue it up for processing
3. Go back to reading from the socket.
This architecture has some clear advantages:
1. Receiving data, and processing data are completely decoupled. As a result of this, you don’t have to worry about IOCP thread starvation. There will always be plenty of threads to service data coming in from the socket, process that data into Xml, and stick it into a processing queue.
2. Logically, the worker threads are simpler to deal with. As the IOCP threads have a clearly defined scope (turn bytes from a socket into xml, and enqueue it) they’re easy to code and debug. The processing threads also have a very defined role (pull data from the queue, and process it). Well defined roles and explicit boundaries between threads means fewer bugs, and easier debugging.
There are some disadvantages to this as well:
1. The penalty for thread context switching is high, and we’re guaranteed at least one context switch per transaction. When we benchmarked this, we saw some fairly ugly performance numbers.
2. In our communication space, packets that come in on a particular socket must be processed in order. This means, in order to keep the worker threads busy, you need to either have a queue per socket or a look-ahead mechanism. The actual problem is this: Let’s say user 1 sends two commands to the server: “This” and “That”. The server begins processing “This” as it was the first to arrive, but now the queue is blocked, because “That” can’t be processed until “This” is completed. Hard problem to solve? Not really – but it’s there and can’t be forgotten about.
3. The locking mechanism on the queue needs to be robust. There are a number of threads reading and writing to the queue (up to 1000 IOCP threads writing to it, and some number of worker threads pulling data from it). This means a reader/writer lock isn’t appropriate, and the only easy way to do this is using Monitors (aka: ‘lock’ in C#). Lots and entering and exiting the monitors. Lots and Lots. Lots! (but hey, monitors are pretty quick, so this isn’t a problem, right? Hah! See below…)
Overall this model worked well, but we just couldn’t get it to scale that well. On a dual processor Xeon box (2.4 ghz, 3 GB of memory, all 32 bit) box we topped out at about 1000 xml transactions per second (a transaction being a Message Echo: Message In, Message out). This isn’t slow but it’s also not fast. Making extensive use of the Compuware Profiler, the SciTech memory profiler, and Windows Performance Counters, we were able to determined that our threading model was holding us back. Too many locks, too many thread context switches.
SoapBox Server, Stage 2
The obvious answer to our troubles is to get rid of our processing queue and our custom thread pool: Process everything in the context of the IOCP thread.
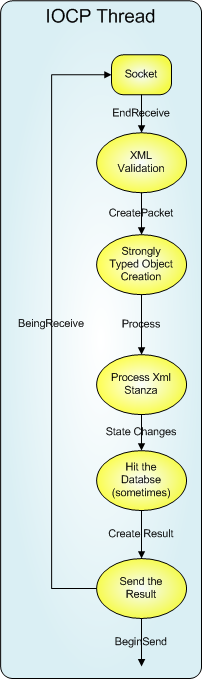
1. Operations on incoming data can be long. Sometimes we have to hit the database, sometimes an LDAP server, sometimes another XMPP server. These can take a long time, and during that time our IOCP thread is blocked. Async database operations weren’t an option in .Net 1.1, and are now only an option when using the SqlDataProvider. They don’t work with Oracle, Postgres, or MySql – all databases that we support.
2. Due to the number of long running operations, we end up with a lot of IOCP threads all alive at once. In fact the number is just scary at times.
There was another subtle problem with this architecture that took us a while to realize: We couldn’t slow things down. We discovered this the hard way – the server would hang, and we would use ADPlus to generate a crashdump. Loading that dump into WinDbg and Son of Strike we would find 1000 IOCP threads (yea, you read that right) all blocked in ADO.Net.
With the IOCP threads all busy doing database reads and writes (or LDAP reads, or AD reads, or any long running operation) the Internal Windows Sockets buffers would fill up. As these internal buffers filled up, client applications would start receiving errors. Once we got into this state, there was no recovering from it short of restarting the process This clearly isn’t good!
Overall this architecture worked well for small scales. Once we had 3000 or more active sockets this architecture started running into the problems described above. (In the general case this architecture could handle significantly more than 3000 sockets, but the customer in question had an LDAP server that couldn’t handle the load. We would see the LDAP server progressively slow down until our threads were essentially locked, then *poof* no more server. Our Dynamic LDAP groups really beat on an LDAP server, especially with caching turned way down so that any changes to the directory take effect immediately).
SoapBox Server, Stage 3
It took a while, but we finally figured out a way to address the issues that we ran into in stages 1 and 2.
As much as we didn’t want to, we reintroduced our threadpool back into the equation. This means data coming in from a socket would once again be put into a work queue. The big difference is where and how we processed data coming off the socket, and the state management around the socket. Once the BeginReceive callback is completed and a work item has been posted to the Queue (complete with the rigth IAsyncResult), we let the IOCP thread just silently go away, to be put back into the pool of available threads.
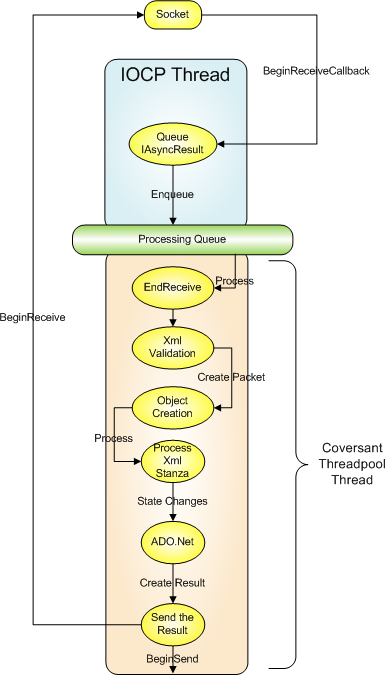
Once our worker thread finishes processing the work item it's last responsibility is to call BeginRead on the socket thereby putting it back into read mode.
This architecture ends up with some nice advantages:
1. We could put a choke on the number of simultaneous operations being processed. By adjusting the size of the thread pool, or the number of active threads in it, we could effectively tune the number of parallel operations. This kept us from crashing LDAP servers, having too much database lock contention in SQL Server, and several other nice benefits. It also let us tune the CPU Utilization of the server so that customers who freak out when they see a CPU spike can now be appeased (I Know. I Know. I am hanging my head in shame. Really. See?)
2. We never have two simultaneous operations from a single user, so the logic for processing work items can be a standard queue. This is because until the work item for user 1 is completed, we don’t even pull data out of the socket for that user. Data just queues up inside the Socket. Go Windows!
3. Overall responsiveness at the socket level is better, as there are always plenty of IOCP threads available to handle requests.
4. In the case of a hyperactive user, that user may see some delays in their messages being handled, but the overall system performance isn’t impacted at all. Other users continue to see a responsive server.
The drawbacks:
1. Well, we’re back to our original performance problem: Every single operation has at least one thread context switch. Data comes in on an IOCP thread and gets queued up. That queue is process by a worker thread. This means there is always 1 context switch per packet. This isn’t the end of the world, but it would sure be nice not to have this.
2. We’ve got locks to deal with again – all writes to the queue mean grabbing a lock, and all reads from the queue mean grabbing a lock. Ah well. Locks are fast. Usually. That’s a whole topic for an upcoming blog…
3. We’re managing our own threads, and we’re not as good at it as the IOCP infrastructure is.
4. This architecture differs from common IOCP architecture in a signifigant way, and that's always somewhat of a risk.
This architecture is where we’re at today. It handles over 100,000 simultaneous users without breathing hard, and has been over 500,000 a few times in the lab (the issue has always been client firepower, not server horsepower). Handling 10,000 to 20,000 simultaneous users is a breeze. We can log in 10k users, log them out, log in 20k users, log them out, and so forth. Everything is very stable.
SoapBox Server, Stage 4
We’ve got a few things planned that we think will help us out a bit more. It’s not clear yet if these are optimizations that we need to make, but should the need arise we may.
The biggest optimization we're looking at is the elimination of thread context switch for very specific, frequent, use cases. Like all applications, there are a few use cases that happen far more frequently than all the others. For us these cases are:
1. User sends a message
2. User receives a message
3. User announces presence
4. User receives presence
These cases comprise the bulk of the work a server does during day-to-day operations. For these use cases we may try to avoid the thread context switch and perform all processing on the IOCP thread. This elimination of context switches should save us a fair bit of processor time.
Some other options involve special casing algorithms depending on usage and processor count. For example: locking the work queue for reads and writes is very quick on a single or dual processor machine. On a 16 processor machine the contention over that lock is pretty scary. There exist thread safe, lock free data structures. These lock free data structures are slower on single and dual processor machines than their locking counterparts, but as the processor count increases their performance stays constant whereas the locking structures see an exponential performance decrease.
We’re also looking and waiting to see what impact the Windows Scalable Networking Pack has on our performance. From what we’ve seen so far, as the number of connections grow the performance of the Windows Network Stack drops off. When profiling our code with a lot of simultaneous connections there are some performance issues that don’t appear to be in our code, but rather inside Windows Sockets. Hopefully the features in the Scalable Networking Pack will address this. All documentation indicates the future looks bright on this horizon…
The Vista and Longhorn network stacks appear to be higher performance than those found in Windows 2003 Server and Windows XP. There may be improvements seen as we migrate to the new operating systems.
Conclusions
The SoapBox Server scales to a frightening number of simultanious users. This is due to the inherent scalability of Windows Sockets and .NET, as well as the architecture chosen inside the application. With the arrival of 64 bit hardware, .Net 2.0, and the addition of some blood, sweat and tears, it appears that the SoapBox Server can vertically scale high enough to handle any load that is realistically going to be thrown at it.
I’m always happy to discuss this stuff, and I’m open to new ideas and thoughts. Please fire away with the comments and questions!