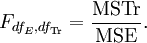Analysis of covariance
From Wikipedia, the free encyclopedia
Analysis of covariance (ANCOVA) is a general linear model with one continuous outcome variable (quantitative) and one or more factor variables (qualitative). ANCOVA is a merger of ANOVA and regression for continuous variables. ANCOVA tests whether certain factors have an effect on the outcome variable after removing the variance for which quantitative predictors (covariates) account. The inclusion of covariates can increase statistical power because it accounts for some of the variability.
Contents |
[edit] Assumptions
As any statistical procedure, ANCOVA makes certain assumptions about the data entered into the model. Only if these assumptions are met, at least approximately, will ANCOVA yield valid results. Specifically, ANCOVA, just like ANOVA, assumes that the residuals [1] are normally distributed and homoscedastic. Further, since ANCOVA is a method based in linear regression, the relationship of the dependent variable to the independent variable(s) must be linear in the parameters.
[edit] Power considerations
While the inclusion of a covariate into an ANOVA generally increases statistical power by accounting for some of the variance in the dependent variable and thus increasing the ratio of variance explained by the independent variables, adding a covariate into ANOVA also reduces the degrees of freedom (see below). Accordingly, adding a covariate which accounts for very little variance in the dependent variable might actually reduce power.
[edit] Equations
[edit] One-factor ANCOVA analysis
One factor analysis is appropriate when dealing with more than 3 populations; k populations. The single factor has k levels equal to the k populations. n samples from each population are chosen randomly from their respective population.
[edit] Calculating the sum of squared deviates for the independent variable X and the dependent variable Y
The sum of squared deviates (SS): SSTy, SSTry, and SSEy must be calculated using the following equations for the dependent variable, Y. The SS for the covariate must also be calculated, the two necessary values are SSTx and SSEx.
The total sum of squares determines the variability of all the samples. nT represents the total number of samples:

The sum of squares for treatments determines the variability between populations or factors. nk represents the number of factors

The sum of squares for error determines the variability within each population or factor. nn represents the number of samples with a given population:

The total sum of squares is equal to the sum of squares for treatments and the sum of squares for error:

[edit] Calculating the covariance of X and Y
The total sum of square covariates determines the covariance of X and Y within all the data samples:


[edit] Adjusting SSTy
The correlation between X and Y is  .
.


The proportion of covariance is subtracted from the dependent, SSy values:


- SSTryadj = SSTyadj − SSEyadj
[edit] Adjusting the means of each population k
The mean of each population is adjusted in the following manner:

[edit] Analysis using adjusted sum of squares values
Mean squares for treatments where dfTr is equal to NT − k − 1. dfTr is one less than in ANOVA to account for the covariance and dfE = k − 1:


The F statistic is